

Mysticial
-
Posts
156 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Events
Blogs
Posts posted by Mysticial
-
-
Errors in the console usually mean hardware instability. The most common one is "coefficient is too large".
I don't know what chip you have, but the usual case is a Haswell chip that is stable enough for normal applications and "light" benchmarks, but not stable enough for AVX. This creates the impression that the program is buggy when in reality the hardware was never stable in the first place.
Haswell with AVX-stability is by far the most common case. But I've seen it on other chips as well. My AMD box gets this a lot when I try to run my 1866 memory at stock. The IMC limits it to 1333, so 1866 is technically an overclock. But y-cruncher seems to be the only app that can expose the (slight) instability at 1866 MHz.
-
I was trying to get my first score... but it wasn't as easy as I thought. All I get is this error message after pressing the submit button. Other HWBOT-integrated benchmarks works fine on this PC, so internet connection is not the issue.

I didn't actually see this until Massman sent me an email. I thought I get email updates to my own threads...
Anyways. What happened was that the benchmark got renamed when it was promoted out of beta. The when program tries to submit using the old name, the server rejects it.
I just pushed out a quick update to fix this issue. But it looks like there's more work to be done on my side of things.
-
I'm struggling with 25M scaling with scaling to 24 threads getting sub 39.85 % multi-core efficiency; with 1B it's better but I'm still only getting 75.56 %. Is there something more to it?
Not really. The 25M is so small that the amount of overhead needed to manage that many threads is significant compared to the amount of computation itself.
In other words, you're not benchmarking how fast you can compute Pi, you're benchmarking how quickly you can create and synchronize threads. Some OS'es do better than others - namely Win8 and Win10 are better at this than Win7 or Linux.
-
I've gone ahead and released v0.7.1 to the public. Let me know how the version turns out.
Here's the first submission for the new version: http://hwbot.org/submission/3216573_mysticial_y_cruncher_pi_1b_core_i7_4770k_1min_59sec_918ms
Download links for the new version are both on my website and the other thread.
And here's a 100b run just because I feel like adding an image to this post.
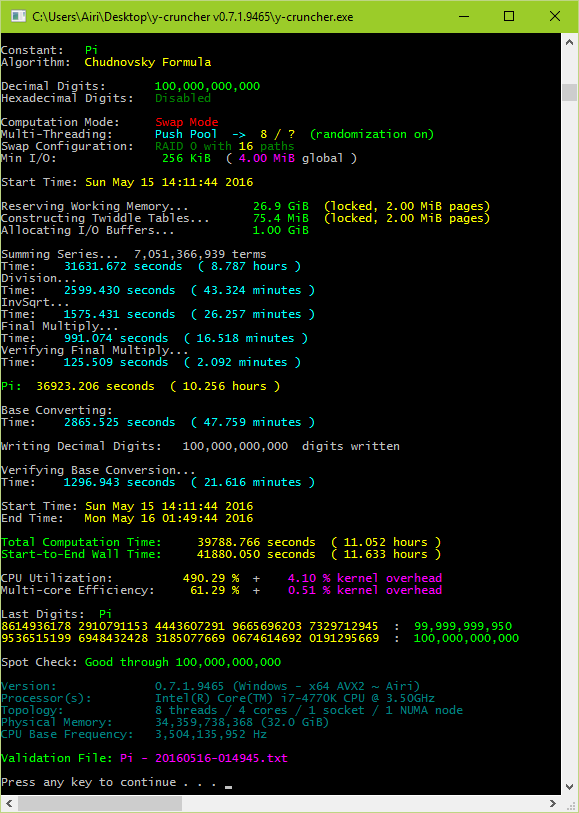
-
Hi Mysticial,
Well I could not at the 4.75 Ghz I was on right now but on standard bios setup non turbo clocked anything the Prime 95 will run smooth it uses about 87% of the CPU usage . But there is exactly the same error on Y-cruncher. For some reason I can neither run GPUPI CPU mode. Meanwhile Geekbench will run as a charm with up to 99% CPU usage.
Regards,
Matsglobetrotter
Just to clarify that I'm understanding your response correctly:
- At 4.75 GHz, neither y-cruncher nor Prime95 will run.
- At stock, Prime95 will run, but only at 87% CPU usage. Neither GPUPi nor y-cruncher will run.
- Geekbench runs with no problems with 99% CPU usage.
If this is the case, then I have no clue. It sounds like something is very wrong with the system. Stuff not working at 4.75 GHz is reasonable. A lot of Haswell-e overclocks at 4.75 GHz are not AVX-stable and will instantly fail on anything that uses AVX (such as y-cruncher or Prime95 28.x).
But if things are failing at stock, then something is messed up. The 87% CPU usage thing is usually an indication that you have background programs running.
- At 4.75 GHz, neither y-cruncher nor Prime95 will run.
-
Hi, I keep getting this error on my Asus X99e-WS with my 5960X anyone know what it relates to?
Modular Redundancy Check Failed
Exception Encountered: generic Exception
Error Code: 2
Regards,
Are you AVX-stable? Can you run Prime95 Small FFTs (version 28.x) for any amount of time?
-
I commented on this a couple days ago.
I also think that a screenshot with the result window and CPUz (CPU + mem) is sufficient. It is not necessary to have the submitter in the screenshot. With v0.7.1 (which I'm ready to release at anytime), there should be no reason to put any OS restrictions.
I also want to make it clear that you are free (and encouraged) to change the computation settings. The default settings that you get when running from the submitter are not always the best. And from my experience, they are rarely optimal when you have 32+ cores.
Everything is allowed (swap mode, using a different binary) as long as you are computing Pi to the right number of digits and it finishes correctly.
I'll keep the submitter app updated to enforce any necessary new restrictions (such as the reference clock stuff).
-
Will the new version support saving data file (for later manual submission via hwbot site) like some other hwbot-integrated benchmarks?
No, but you can (almost) already do that by saving the validation file. I can't allow manual submissions until I have a mechanism to block submissions into the wrong category. (i.e. submitting a 25m into the 1b.)
-
The beta competition has been winding down for the past couple weeks and it officially ends in two days. So I thought I'd shed some light on what's potentially coming next.
y-cruncher v0.7.1 has been in feature freeze for the past 3 weeks and I've started handing out a release candidate to a handful of people. In other words, it's almost ready. If any staff members are interested, PM me or shoot me an email.
The new version has a bunch of changes. The ones that are relevant to HWBOT are:
- Admin is no longer required to run. But turning it on anyway may give a small speedup. Admin is still required for swap mode.
- Detection of the operating system.
- Detection of more hardware components. (HT, # of sockets, motherboard, memory)
- Detection of the reference clock. Version 0.7.1 will now recognize the TSC, HPET, and ACPI reference clocks. The submitter will refuse to submit benchmarks that are run Windows 8 or later if the reference clock is not HPET or ACPI.
- Performance improvements for most processors. And a new binary aimed at Broadwell and Skylake desktop chips.
This version adds a lot of environment detection mostly for validation and to streamline the submission process. At the very least, the motherboard and # of processors will now auto-fill themselves (if HWBOT recognizes it). On Windows, it will also detect the individual memory modules, but HWBOT currently doesn't take this information. (I couldn't figure out how to do this on Linux.)
OS and reference clock detection is obviously for validation and to lift the Windows 8 and later restriction. However, I found out today that this might not be 100% reliable. Apparently my laptop's platform clock is neither HPET nor ACPI. y-cruncher doesn't recognize it and the submitter blocks me from submitting anything run on my laptop. After a bunch of Googling I still couldn't figure out what the hell it is. In any case, this is something that can probably be fixed on the submitter side. So I'm fine with rolling out y-cruncher as is.
Last are the performance improvements. They aren't massive speedups. (Mostly around the 1 - 5% range.) Last time I checked, Sandy/Ivy Bridge with AVX had the biggest improvement. But still nowhere near enough to be competitive with Haswell/AVX2. Those with Broadwell and Skylake will be able to run the new "x64 ADX ~ Kurumi" binary that utilizes the ADX instruction set.
Unfortunately, this means that v0.7.1 will not be speed consistent with v0.6.9 and older versions. So if y-cruncher is here to stay on HWBOT, this is something we'll have to live with since y-cruncher probably continue to get incrementally faster with major release. With respect to that, I have AVX512 binaries lined up and good to go. So expect a potentially "unfair" advantage for Skylake-EP and Cannonlake whenever I can get my hands on them. (Knights Landing also has AVX512, but that's still uncertain since the architecture is so drastically different.)
----------------
In any case, there are some open questions:
There's a new version of the submitter that will be released simultaneously with y-cruncher v0.7.1. Right now, that submitter is set to block all v0.7.1 submissions on Windows 8 or later if they aren't using HPET or ACPI. Should I extend this to block earlier versions of y-cruncher that cannot detect the clock? This means that the current version of y-cruncher will no longer be usable for HWBOT.
What about Linux? I have no idea how easy it is to tamper with the clocks in Linux. (I've never tried.) But it's certainly possible since Linux is open-sourced. So a capable kernel hacker can modify it in a way to trick y-cruncher's timings.
When should I actually release v0.7.1? Should I do it immediately after the competition ends? Or should I wait around a bit. (I'm not sure what usually follows a beta competition.)
- Admin is no longer required to run. But turning it on anyway may give a small speedup. Admin is still required for swap mode.
-
Solved , copied at C:\ , and dismark only read at directory.
Excellent. I'll make the error-message more specific for the next version. You probably won't be the last one to hit this.
It just occurred to me that not being able to write to disk will also prevent the submitter from running y-cruncher at all since it uses scripts.
-
Yes , the data file is missing ....
I download the benchmark and unrar file at HDD USB after I copied the directory to another PC on R5E and 5960k.
Posible is blocked from permissions ? How can I solved it ?
The JAVA version its for x64 but not the last 9.JRE its 8.JRE.
While I'm not 100% sure this is the case, I do agree that it sounds like the submitter can't write to disk at all. Where did you put the y-cruncher folder? If you copied directly into "c:/" there's a chance that it won't have permissions to write there.
Try copying it somewhere else on that system. If the problem persists, then I'll have to push out a new version with some additional logging to pinpoint the error.
-
Hello ,
On Win 7 , R5E , 5960X , show launcher Error on create data file , unable to create ... what happens ??
How can i solved it ?
Thanks !!
PD : On Win 7 , 2600k , not problem.
Just to make sure I know which error message you're getting. The exact text reads, "Unable to create datefile." right?
Do you see a file named, "datafile.hwbot" in the path where you are running the app? This error message will show up if the submitter app is unable to write to the directory that it's running from.
-
Can't wait to see the results

Fine...
 I hope I don't get yelled at.
I hope I don't get yelled at. -
Alright... Someone in China was kind enough to give me remote access to a dual Xeon E5-2696 v4 (Broadwell-EP)
It's got 44 cores/88 threads and 768 GB of ram. And after playing around with it for a few hours, I have some benchmarks for it.
Does anyone mind if I lay waste to the leaderboards?

I feel very guilty just thinking about it since I wrote the benchmark.
Btw, getting the program to run efficiently on these high-end boxes is actually quite difficult. At this level, the program is very sensitive to a lot of things. Combine that with a half-dozen knobs to turn within the program and it's a very large search space to play with.
-
Thanks. Though on second thought, I'm not sure if I'll be able to run any valid benchmarks on them. They're all running Windows 10, and I don't think I have permission to touch the bootcfg to turn on HPET.
-
What's the policy of borrowing or loaning hardware?
Someone has offered to give me remote-login access to a number of systems including a dual Xeon E5-2696 V4 (Broadwell-EP with 44 cores/88 threads and 768 GB of memory).
The purpose of this is to do scalability tuning for y-cruncher. But I am also authorized to run and disclose benchmarks on this thing.
Would it be bad taste to submit benchmarks from hardware that I do not own?
-
thought so , maybe via a batch file?
I don't see how a batch file would help anything. What did you have in mind?
-
guys i have an i7 3820 at 4.9ghz and im getting horrible times anyone knows why??
i get 3.265sec on the 25m
and 225.801 on the 1B
there are core i3 better then this =/
Sandy Bridge processors don't have AVX2.
-
one nice feature to UI , adding swap mode, because for total novice this will be very difficult to do via command line..
but so far very good..
I've thought about that. But swap mode is part of the custom compute menu. And that custom compute menu is f:D:oking complicated. So it will take a lot of work to mirror that menu into the UI.
Aside from that, there are some technical roadblocks. The custom compute menu is an interactive menu. Unlike the benchmark menu, you can't just fire a command at it and expect it to always work gracefully.
The custom compute menu will show memory calculations and warnings. It will also hide/disable options that aren't applicable or are incompatible with existing settings. And it will automatically adjust things in response to user-input.
But in order to do that in the UI, y-cruncher needs to be able to send information back to the UI. Unfortunately, that's not possible right now. And I don't know how to do it that atm. That said, I can try to design something around this limitation, but no promises.
-
I was going through the submissions and I noticed a number of multi-socket systems that have seemingly terrible performance. (Especially that 4-socket Magny-Cours Opteron.)
I'll go ahead and explain why this is the case. It will probably be obvious to those of you who are familiar with the topic.
-----
Why does y-cruncher (sometimes) suck on multi-socket systems?
This is due to memory access. Specifically, Non-Uniform Memory Access (NUMA).
y-cruncher can only run efficiently when the following assumption is true:
- Every core/processor has fast access to all the memory.
This is true for all single-socket systems as well as some of the pre-Nehalem dual-socket servers. But not on modern multi-socket systems.
On multi-socket systems, each processor socket has its own set of memory banks. A processor has fast access to its own set of memory. But if it needs to access memory that's elsewhere (on a different socket), it needs to go over the interconnect to get it from the other processor. So it's a lot slower.
In other words, the assumption that is critical to y-cruncher's performance is no longer valid. Some memory is faster, and some memory is really slow - hence "Non-Uniform Memory Access". If you have two sockets, half the memory will be fast and the other half slow. If you have a lot of sockets, then the vast majority of the memory will be slow with respect to each individual processor.
If you think that's bad, get ready for more bad news.
Operating systems are aware of the NUMA. So they try to be smart about it. When a program runs, it biases the memory in favor of the core that asked for it. This maximizes locality so that memory access stay within the same NUMA node. While this sounds reasonable for most applications, it actually backfires for y-cruncher. Unlike most programs, y-cruncher wants to use the entire system.
Some of you might have noticed that y-cruncher's memory usage is static throughout the entire computation. What's happening is that y-cruncher allocates all the memory it needs upfront and reuses it through the computation. And that's where the problem is. That allocation is done by a single thread. So the OS will put all of it on one NUMA node.
During the computation, y-cruncher spawns threads that run on all the cores and all the sockets/NUMA nodes. Since all the memory is on one socket, all processors from all the sockets will hammer that one socket. Not only is it overloading the memory bandwidth in that node, it's also swamping the QPI going in and out of that socket. Meanwhile, all memory on the other nodes are idle. In other words, a massive traffic jam while everybody tries to park in one garage while there are 3 others that are empty.
This is why the performance sucks on those quad-Opteron servers. It also affects Intel machines as well, but to a lesser degree since they seem to have better interconnects.
What can you do about it?
The biggest problem is the traffic imbalance. If your BIOS has the option to disable the NUMA, then do it. This doesn't actually disable the NUMA since the NUMA is a physical thing, but it tricks the OS into thinking there's no NUMA so it randomizes the memory allocations across all the nodes.
In Linux, you have a bit more control. The numactl package lets you run a program with interleaved memory. This also spreads out the memory across the nodes.
These tweaks will help y-cruncher run faster. But it doesn't completely solve the NUMA problem. There's still the latency problem, and even when the interconnect traffic is balanced out, it will still be a bottleneck.
Solving the NUMA problem can only be done by redesigning the program. That's obviously beyond the scope of benchmarking.
That said, it doesn't mean you should avoid multi-socket systems. A high-end dual-socket machine that is properly configured will still beat out all the single-socket setups - LN2 or not.
What makes y-cruncher different from programs like wPrime?
y-cruncher actually needs to use memory - and a lot of it. (Not that I needed to say that.)
- Every core/processor has fast access to all the memory.
-
yes i don't see the message, "Sending datafile. Please wait..."
i am alredy waiting 8 minits sind the last try
Try this one and see how far it gets.
Version 0.9.3.95: http://www.numberworld.org/y-cruncher/HWBOT%20Submitter%20v0.9.3.95.jar
I did manage to hack in a progress counter for the submission.
When everything works properly, you should see things in this order:
- Building datafile. Please wait...
- Sending datafile. Please wait...
- Sending: XX.X MiB / XX.X MiB
That last one will refresh every second until the submission is complete. Then it disappears. If any errors occur, there should be an error-box that pops up. If something crashes, you probably won't see anything and it will hang.
Anyway. I need to get some sleep. So I probably won't be able to respond for quite a while.
- Building datafile. Please wait...
-
submition working whit out the screenhot.
but if i click take a screenshot furst and than submit. noting happens ,no message : sending datafile, pleas wait
So you do not see the message, "Sending datafile. Please wait..."?
It may take a few seconds before the message pops up. But if you have a slow internet connection or a really large screenshot, then the actual sending may take a while. It takes 20+ seconds for me if I try to upload a 1440p image. And my connection isn't the worst one out there.
It sounds like I need to make the send progress more explicit. That way even when it's not working, it's clearer where it gets stuck. Unfortunately, I can't do a progress bar since the Java network API doesn't seem to have any way to relay that information back to the caller.
-
Submission worked here: http://hwbot.org/submission/3189693_massman_y_cruncher_pi_25m_core_i7_4500u_12sec_927ms
I'm super impressed with the integration, @Mysticial, brilliant approach to the integration problem. If all benchmarks would have a submit function like this, part-taking in OC would be so much easier!
That's a pretty low bar to be "impressed" by.
 If I tried to present this to the UI folks back when I was at Google, they would've blown me off and told me to go back to programming.
If I tried to present this to the UI folks back when I was at Google, they would've blown me off and told me to go back to programming.In all seriousness. I'm also a user of the app. So if something doesn't feel right, or inconvenient, I'll tweak it until it does. After a few iterations of that, this is what it converged to (at least for my workflow).
The screenshot one was particularly tricky since I didn't want to over-complicate the UI. Screenshots are very invasive and can capture sensitive stuff. So I wanted the user to know exactly what he/she is about to send before actually sending it. And then there was the horrific side-effect of making the datafile really big and taking 20 seconds to send and freezing the app for the entire time. (My 2560 x 1440p monitor screenshots to a 2MB png.)
-
for me the new Version is not 100% ok.
i can run ,but submition butten don't work.
and manuel submitting give : Invalid data file: Unable to decrypt the datafile
Ugh...
Manual submissions have always been disabled for reasons I mentioned in the other thread.
In what way is the submission button not working? It doesn't do anything when you click? When you click it, do you at least get the status update on the bottom right corner?
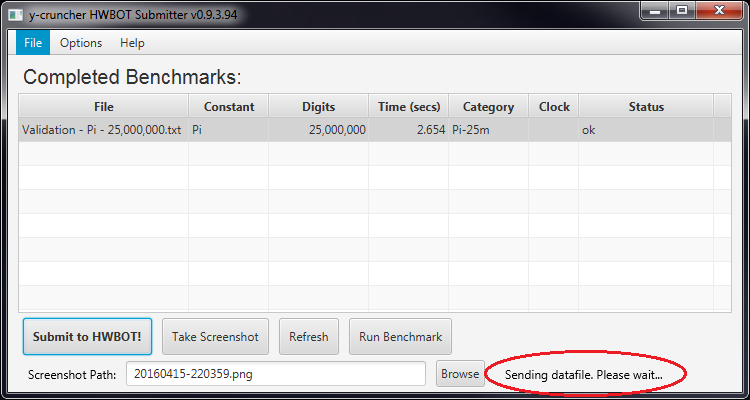
The behavior of that changed since the last version. Previously, the entire app would freeze while it sends out the datafile. But with screenshots, the datafile is much larger. So depending on your internet connection, it may freeze for a long time. So I changed the implementation so it wouldn't freeze but would at least display an indicator that it's still sending.

Math turns benchmark: y-cruncher meets HWBOT
in Benchmark software
Posted · Edited by Mysticial
I'd like to bring back the topic of HPET platform timers and open up a discussion about virtual machines (VMs).
y-cruncher submissions to HWBOT currently require either HPET or ACPI for Windows 8 and 10. But I've come to realize that there are other platform clocks out there. When you use bcdedit to force on the platform clock, you're not guaranteed to get either HPET or ACPI.
My very own laptop seems to use an unknown platform clock which I've been unable to identify. Since neither y-cruncher nor the HWBOT submitter is aware of this clock, it blocks me from submitting benchmarks from my laptop.
The broad problem is that only the TSC clock is affected by the clock skew on Windows 8+10. Does anyone mind if I change clock enforcement to blacklist TSC rather than whitelist HPET and ACPI? This should allow all other platform clocks.
The downside of this is that it also allows VM clocks. Some of the Linux benchmarks that I've gotten from people use the "xen" VM clock. But that seems to be mostly a Linux thing. VMs in general are difficult to tackle since they (by design) attempt to trick the software into thinking it's running natively. So everything from clocks to instructions can (theoretically) be faked. y-cruncher v0.7.1 will attempt to detect if it's in a VM. But it currently doesn't block VM benchmarks because:
Speaking of Linux, the submitter currently does not block any Linux submissions regardless of the reference clock. So you are (technically) allowed to run benchmarks in Linux, take a screenshot there, then transfer the files to Windows and submit to HWBOT. But given that there's no CPUz for Linux, this probably won't work for the majority of the competitions.