Mysticial
-
Posts
156 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Events
Blogs
Everything posted by Mysticial
-
Please delete: https://hwbot.org/submission/5355456_mysticial_y_cruncher___pi_25b_core_i9_7940x_14min_9sec_662ms I forgot to include CPUz.
-
The version information is already embedded in the datafile as metadata. Assuming HWBOT keeps its datafiles, you can retroactively go back and parse that information on all existing submissions. In fact, the entire validation file that y-cruncher generates (which contains everything you need to know) is also embedded in the datafile. At least for submissions using the HWBOT Submitter. I dunno about the BenchMate submissions. So the data is there if you need it. Though it may not be convenient to access. If you want the version information in a different place, I can do that.
-
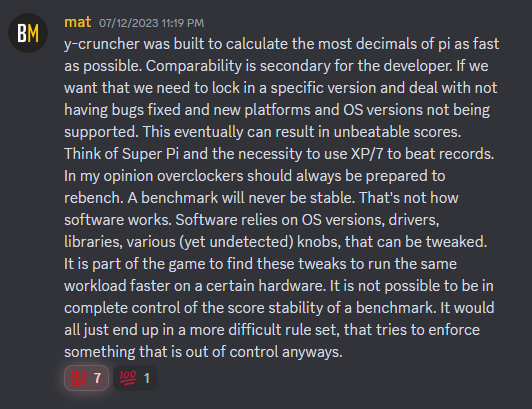
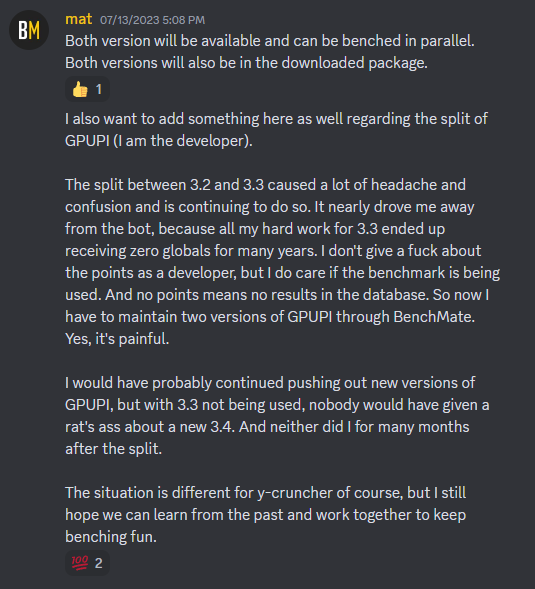
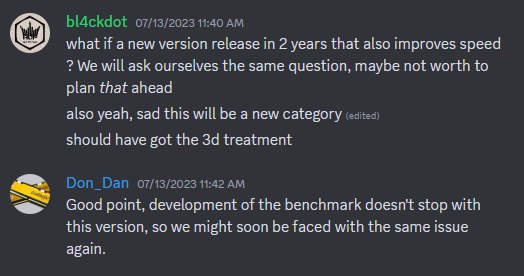
Apparently this was discussed in Discord. Posting a few key points here. To be clear, I have no preference on what HWBOT decides to do. I'm not a competitive overclocker and thus cannot make an informed decision. I'm just happy to see that people like the program as a benchmark. But as the developer, I can confirm that I will not and cannot maintain multiple versions of y-cruncher. This is simply not a feasible task given how volatile modern environments are with operating systems, development toolchains, etc... Therefore, development will only be on the latest version. So support for future technologies like AVX10 and APX will only be on the latest version and not backported to old versions. Likewise I cannot fix issues with old versions even if they break in a way that makes them unusable. As mat has correctly mentioned, y-cruncher is a scientific program first, benchmark second. The goal is to compute many digits of Pi as efficiently as possible by any means necessary - both hardware and software. Competitive overclocking is only the half the equation. I can also confirm this. There are many optimizations that I omitted when I rewrote the core algorithm in v0.8.1. If and when I feel like re-adding them, you can expect the program to get faster again. And of course this says nothing about future (unknown) optimizations. Right now, there's 1b, 2.5b, and 10b. And I think 5b and 25b will be added soon. That's 5 categories. If we then split this up by version, we're looking at 10 categories or more if future versions get faster. So I can see how this can get cluttered under the current HWBOT system that lacks version tracking/filtering.
-
Yeah, that "bug" with y-cruncher running in low priority is because it explicitly sets its own priority to below average on program launch. Thus it overrides whatever environment setting there is to launch it as. Only the built-in priority option can change this behavior. I didn't realize this was a big deal until I watched one of Buildzoid's streams and he spent a silly amount of time trying to work around this. And he couldn't add extra parameters to the command line.
-
Is it possible to allow the user to edit the command line that's used to launch a benchmark? For example, you can't add "-TD:24", or "priority:2" without running outside of Benchmate and submitting separately.
-
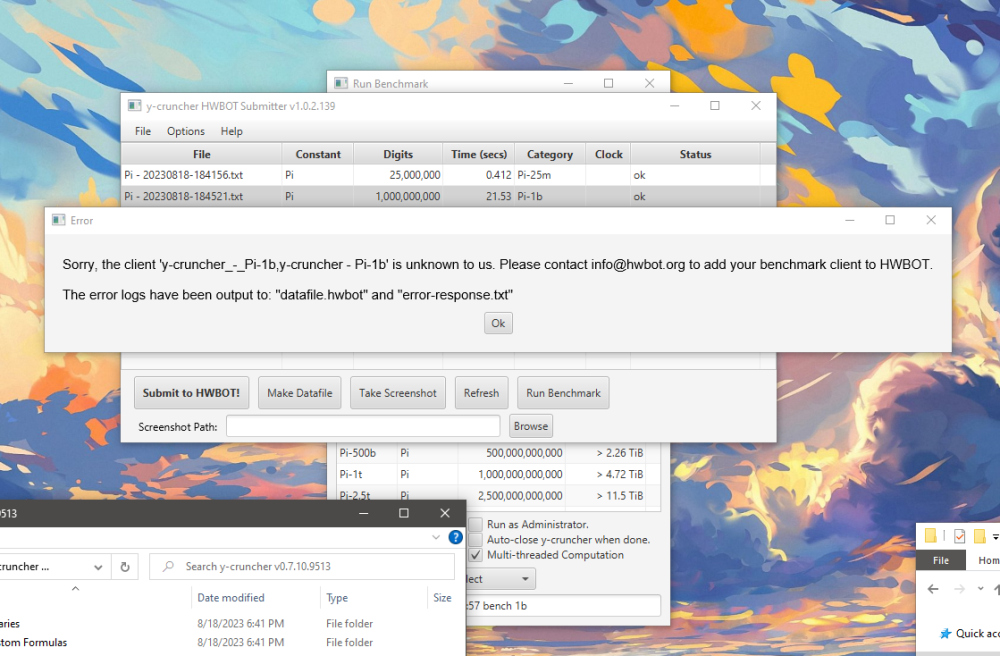
Cannot submit any y-cruncher benchmark.
Mysticial replied to Mysticial's topic in Submission & member moderation
Here ya go! pi-10b-v0.7.10.hwbot pi-10b-v0.8.1.hwbot pi-10b-v0.8.2.hwbot -
Developer here. I just noticed that I'm unable to submit y-cruncher benchmark with the old versions (v0.7.10). If I include the screenshot attachment, I get access denied. Did something change server side?
-
Since it looks like 30+ people voted to keep as one benchmark, I'm going re-add the HWBOT submitter app for v0.8.2 and will be backward compatible with v0.8.1. Since v0.8.2 is (likely) getting released next month, I won't bother re-releasing v0.8.1 with the HWBOT submitter app. If staff wants me to hold off, let me know.
-
FWIW, I expect v0.8.2 to go out in the September time-frame. Way ahead of schedule. What I thought would take months ended up taking only 3 weeks. I don't expect any major perf changes this time. (though there's a potential it will reclaim some of the perf loss on the oldest chips) Nearly all the work has been in swap mode which is not used in competitive.
-
How often does the driver change relative to the rest of BenchMate? Can they be separated so that BenchMate can be updated without touching the driver?
-
Bumping this so it doesn't fall off the radar. Since nobody can submit v0.8.1 scores anywhere yet.
-
y-cruncher always doubles up the # of threads/tasks if the core count is not a power-of-two. Is this backfiring only on the Zen4 7900X? Or is it backfiring on older chips as well. This is something I added many years ago to help get around load balancing issues of running DnC algorithms on non-power-of-two core chips. But I've never re-evaluated whether that is still helpful. upL_t BasicParallelism::default_tds(){ upL_t tds = Environment::GetLogicalProcessors(); // If it's not a power-of-two, double it up to help alleviate load imbalance. if ((tds & (tds - 1)) != 0){ tds *= 2; } return std::min(tds, (upL_t)YMP_MAX_THREADS); }
-
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
This is fundamentally not solvable. You would need something similar to what the Nintendo Switch does with a dedicated security chip that does the encryption/decryption. The chip itself has the key burned into it and all use of the key is inside the chip itself. I'm not sure if TPM can be utilized to make this possible. The main problem here is getting the BenchMate key into the TPM in a way that cannot be eavesdropped by a listener. You could probably do it using public-key encryption, but you can't easily stop someone from impersonating the TPM and tricking BenchMate into sending it the encryption key which can then be decrypted and recovered. -
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
How difficult would it be to change the 2.5b submission keys to keep everything consistent? /cc @Leeghoofd I can give both of you the formula I used to generate the keys for all y-cruncher submissions - of all sizes. -
This makes me wonder if HWBOT should have a built-in versioning system. This is neither the first nor will be the last time that a benchmark will change like this. So maybe a versioning system that lets people filter or aggregate results by version.
-
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
That was fast. ? Judging by the poll in the other thread, it looks like things might be staying the same. The HWBOT submitter has some formula that generates the submission keys for all the sizes. (obviously not hard coded) So it will let you try to submit any size. Except that the 2.5b size was added to HWBOT without coordinating with me so it uses a different key from the one I would have entered into the system. (as you mentioned, we no longer have access to the benchmark configs) If we decide to extend the sizes on the same benchmark, I can send you and @Leeghoofdthe keys for all the sizes to use in the future. (everything from 25m all the way to 1t+) -
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
I haven't actually picked those yet since they're normally set by the HWBOT submitter app. (which I haven't updated for v0.8.1) Question: Do we want to continue with the dual HWBOT submitter + BenchMate support? Or do we want to move forward with only BenchMate? If the latter, then you are free to pick your own submissions keys. (I assume you're parsing the validation file right?) If the former, then I'll need to time to update the HWBOT submitter app with the new set of keys. -
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
y-cruncher v0.8.1 got released yesterday. I've intentionally withheld HWBOT support until we decide what to do here. -
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
Another thing to keep in mind is that not all the perf changes will be coming at once. It will *start* with v0.8.1. But, more optimizations may be coming in the following releases. It's a very big rewrite and thus will not be done all at once. I've done enough to reach parity on the Bulldozer line (the oldest chip I still care about). So I'm drawing the line there for v0.8.1. There's still optimizations which have not been done. If and when I do them is TBD but will be after v0.8.1 (I estimate in the v0.8.3+ timeframe). For now, I'm shifting priority to finishing other parts of the rewrite like swap mode (which isn't relevant to HWBOT), then coming back later to do optimizations. That said, I expect the big change to be v0.7.10 -> v0.8.1. I don't believe what's left to be more than single-digit % swings, but I have surprised myself before. I expect v0.8.1 to be out within a month assuming nothing major shows up during testing. OTOH, I have no timeline for the 2nd round of optimizations. Though the goal for now is to coincide with Zen5. (which could be early again if AMD sends me one like last time) -
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
To expand on your idea of splitting out separate versions for every major perf change, you could also keep an "anything goes" category where you're allowed to use *any* version of y-cruncher. That way old chips can use old versions that still have optimizations for them while there's no holding back to the latest either hardware or benchmark tweaks. -
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
Yes it will be large. Potentially double-digit % in both directions depending on the processor. In particular I'm removing a lot of optimizations for things that are more than 10 years old because they are no longer relevant to the new stuff and are just a maintenance burden for development. Will be a while before there's build ready as it's not done yet and there's still an tremendous amount of testing to do. Mostly likely, things will roll out incrementally over multiple releases of v0.8.x. I can hold back HWBOT submitter support on v0.8.x until things or ready. Or retire the submitter and hand it off to BenchMate. Will probably be a config file for starters since there's no UI built into the main program. I'm currently 50/50 on whether to do this as it will depend on how much the parameters actually affect perf. It won't be in first release (v0.8.1) since there's already enough complexity to validate and test. You can kinda already do this. BenchMate sends a command to the program. Instead of the "bench" command, you can send the "custom pi -dec:2b" command and it'll do it. I may need to add some extra lines to the spot check files if there aren't already entries for it. This won't work with the HWBOT submitter though. -
Possible upcoming y-cruncher v0.8.x Tweaks
Mysticial replied to Mysticial's topic in Benchmark software
Some other mitigations to consider if such parameters were exposed. Require HWBOT submissions or per just within the scope of a competition to run with certain parameters locked. This forces a level playing field. If parameter changing is allowed, require that all submissions either show the parameters or have them downloadable for others to copy. -
Developer of y-cruncher here. Looks like a lot has changed since I've last visited. 2.5b is now a thing, but only under BenchMate presumably because I never gave Hwbot the decryption keys for it. (Yes, the program has decryption keys for all the benchmark sizes, but I only submitted the ones for 25m, 1b, and 10b into the system when I first added the benchmark years ago.) Anything I can do here to make things compatible again? (or just just drop the submitter since BenchMate looks superior in every way) Staff can DM or email me to take this offline. -------- In any case, the reason why I'm here is that y-cruncher v0.8.1 is coming out soon (1-2 months?). Internally a bunch of stuff is getting rewritten so there will be large performance swings from v0.7.10. One of the things I'm considering changing is to expose more of the program's tuning parameters. For example, each of the binaries have tuning tables that are currently hard-coded. Here is a (semi-contrived) example for cache management: // size, sharing, explicit/implicit, flags { {(upL_t)512 << 10, 1, true, LoadType::NORMAL, StoreType::NORMAL, PrefetchType::PREFETCH_T0}, {(upL_t)1408*18 << 10, 36, true, LoadType::NORMAL, StoreType::NORMAL, PrefetchType::PREFETCH_T1}, {(upL_t)-1, 0, false, LoadType::NON_TEMPORAL_PREFETCH_NTA, StoreType::NON_TEMPORAL, PrefetchType::PREFETCH_T2} }; Don't understand it? That's the point. The average person won't know what to do when thrown into a 747's cockpit. Many of these (hard-coded) tables are extremely specific to the set of processors that I tune the binaries on. And even within the same processor class one set of settings which are optimal for one chip may be actively detrimental to another. For example, the above is for the Skylake X 7980XE. But it is actively detrimental to the lower core-count chips of the same line. To summarize, the purpose of exposing more settings is to allow users who know what they're doing to improve performance. However, these parameters are difficult to touch if you don't know what you're doing. Thus it inherently gives an advantage to those who know what they're doing. You can think of this as a motherboard suddenly exposing secondary and tertiary DRAM timings for an OC competition. But instead of for the hardware, it's for the benchmark itself. So what are people's thoughts about exposing these internal benchmark parameters? How much havoc would it wreck on competitive OC'ing? Intuition tells me that these internal settings will be welcomed by the folks chasing Pi size records since those tend to run for many months at a time. (Yes, those many-trillion digit computations that require petabytes of storage.
-
Benchmate 10.6.8 is out!! NO MORE SUPPORT FOR GEEKBENCHES!!
Mysticial replied to Leeghoofd's topic in HWBOT News
Is the key an unobfuscated plain text string or something? (not saying mine is much better...) -
Benchmate 10.6.8 is out!! NO MORE SUPPORT FOR GEEKBENCHES!!
Mysticial replied to Leeghoofd's topic in HWBOT News
Great! Part 1 done. Now we just need to advertise it and get everyone in the world to submit fraudulent scores! While I have a vision for what such a GUI would look like, it's unlikely that I'm personally gonna ever do it. I have neither the expertise, time, nor interest to do it. But there is a partially completed API layer that would allow 3rd parties to integrate with y-cruncher and become the GUI themselves. But realistically speaking, unless there's someone willing and able to volunteer that kind of time, it's not going to happen. Yeah, been there done that in multiple ways (specifically with y-cruncher). It's not that simple.