_mat_
-
Posts
1003 -
Joined
-
Last visited
-
Days Won
41
Content Type
Profiles
Forums
Events
Blogs
Posts posted by _mat_
-
-
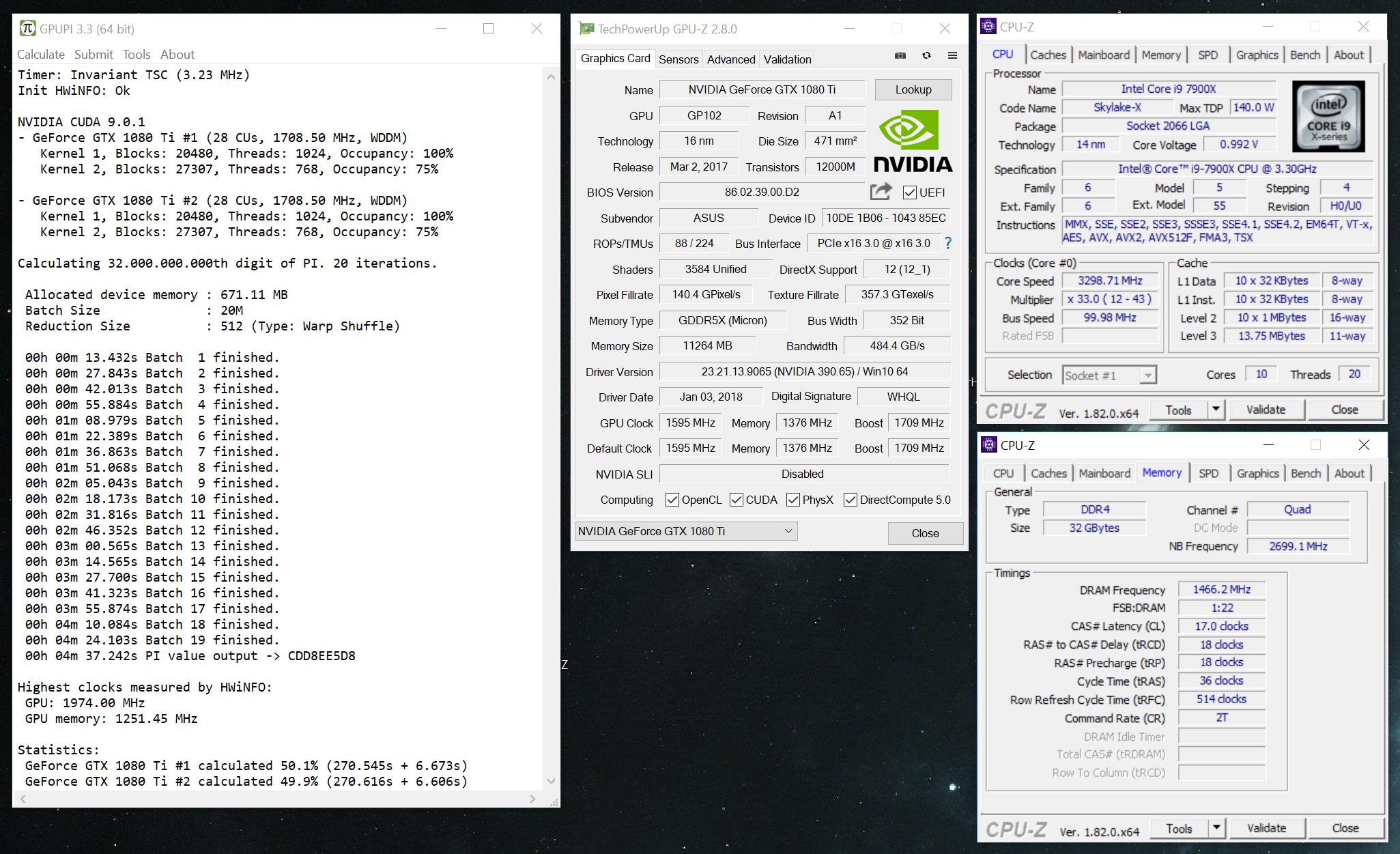
Nice clocks! Use CUDA with NVIDIA cards, you will cut another two seconds of that score.

-
I would say that there is a good chance that a decent chip, although not the best, won't get as much attention as the best samples and can be an overlooked treasure. Some chips (and certainly not all) require a huge time investment to figure out how to get past their handicaps. These might coldbugging, illogical and bad mannered bastards but they can still be a winner.
-
That's a CUDA error, that happens directly after the calculation kernel when waiting for the GPU to return the data. Something like this occurs for example when there was something wrong with the memory (read or write in unallocated areas). Is the card heavily overclocked? Are you using high batch and reduction sizes? Try stock clocks and the lowest sizes and see if that's the problem.
Btw, you should have also gotten a detailed error message in square brackets right next to the error you posted. Please let me know what it is.
-
Very strong for "only" four cards! Nice score!
-
Out of the shadow of Titan X, you must rise. Find the light, you will!
-
Damn, Titan X is really, really fast!
-
Damn indeed!

-
-
Wow, Hawaii is still going strong! Congrats!
-
11 cards!! So awesome!
-
The end validation has not changed at all. But if you are using CUDA, the kernels have changed so it will be harder on your GPUs. Try to reduce oc or increase voltage/cooling.
-
Yes, use 2.3.4 it fixes all fo the sync and validation issues with multiple cards.
Btw, 2.2 had no runtime validation, it only validates the final result. That's why it works.
-
Awesome! Thanks for your feedback.
-
I fixed it, but couldn't make it run in a virtual machine because I can't install OpenCL. Please redownload this version and try again: https://www.overclockers.at/news/gpupi-2-3
-
I have not tested the Legacy version yet. It was compiled with VS 2013 (instead of 2012) which introduces some major changes. I will have a look at it as soon as I have more time.
Btw: I don't know if I will continue to support the Legacy version. It's a lot of work and has very few downloads. This may be the last version.
-
For the purpose of full exposure, I am posting this here as well. After lots of hours of bugfixing version 2.3 is finally bulletproof. Please redownload the newest build for before benching: GPUPI 2.3.4
Additionally the following features were added in the last four minor version:
- Supporting Tesla graphics cards
- Support for more than 8 devices - theoretically thousands of devices could be used for calculation now!
- Detection of AMDs RX 480 graphics cards
- Important bugfixes for the Legacy version and GeForce 200 series cards
- Cleanup for source code
Download: https://www.overclockers.at/news/gpupi-international-support-thread
Many many thanks to dhenzjhen again, because of his support GPUPI is now better and more flexible than ever! If you haven't seen his score with 10 Tesla M40s you better do it now: dhenzjhen`s GPUPI - 1B score: 2sec 621ms with a GeForce GTX 1080 (it's momentarily filed under GTX 1080 because the M40s are not in the database)
- Supporting Tesla graphics cards
-
Try 20M and 512 reduction size, it should be about a second faster than this result.
-
Just a quick heads up! Tomorrow I will release GPUPI 2.3 with multiple bugfixes and features. I am very happy with the new support of CUDA 8.0 plus serveral optimizations of the CUDA kernels that finally led to faster scores than the OpenCL implementation.
Have a look at this score with a GTX 1080, it's top 10 on air cooling - and my sample doesn't really clock well:

So hold your horses for now if you are benching NVIDIA cards with GPUPI.
-
Well, that was inevitable - GTX 1080 is the new champ in GPUPI!
Congrats, Dancop! Awesome work!
-
Nice and thanks for reporting back! Added both solutions to the FAQ.
-
Awesome work and congrats!
-
No, it's not necessary. OpenCL works out of the box when installed on the system.With gpupi 2.2 am I supposed to have opencl drivers in the gpupi folder, like the cuda drivers are? Because I dont have those in my folder when I download gpupi.
-
I don't know what Geekbench really does when benching memory. If it's mostly a bandwidth test, it should be affected as well.
The gap between 4/512 and 1/64 says a lot. The more the batch size is adjusted to the architecture itself, the faster the bench will be. That's because the workload is aligned to the maximum worksize, that can be run in parallel. 4M seems to be the best choice for the 6100 with 2 Cores/4 Threads.
About the same is true for the reduction size. The bigger the better, because 512 means that 512 sums will be added up to one until only one sum remains. Lets say that we want to sum up 8192 single numbers, that would be:
step 1: sum of 512 numbers, sum of 512 numbers, ... (16 times)
step 2: sum of 16 numbers = result
Where as the reduction size of 64 would produce:
step 1: sum of 64 numbers, sum of 64 numbers, sum of 64 numbers ... (128 times)
step 2: sum of 64 numbers, sum of 64 numbers
step 3: sum of 2 numbers = result
If you consider that GPUPI produces billions of partial results, that need to be added up, then 512 also needs a lot less steps in general to sum up the batches after they are calculated. Additionally the bigger the batch size, the less reduction process have to be made for the calculation. So these two values mean a lot for the whole computation.
-
Have you tried a memory benchmark yet? Try AIDA64 to test your bandwidth, it should be impacted as well: Overclocking, overclocking, and much more! Like overclocking.This is so strange, it's the only bench I have ever had an issue that I couldnt eventually figure out. I guess I should try with different mobo and cpu.Otherwise it's a driver issue, but I doubt it. We never had an efficiency problem with the memory reduction before. It's btw a very common technique for summing up a lot of memory in parallel. The pi calculation itself depends on much more to be efficient.
marc0053 - Titan X Pascal - 10sec 144ms GPUPI - 1B
in Result Discussions
Posted
So close to breaking the 10s barrier! Congrats!