_mat_
-
Posts
1003 -
Joined
-
Last visited
-
Days Won
41
1 Follower
_mat_'s Achievements
")





-
Yes, there is a problem with the hwbot certificate on your system. It has a fairly new root or intermediate certificate from their certificate provider, iirc. Normally this happens if the bench os has not been updated in a long time, or hasn't had an internet connection in a while. Many certificates in the Windows certificate store won't be valid anymore and that breaks the certificate chains. The easiest way is to update. I tried to solve it in the manual BenchMate installation but failed to fix it. I will try again soon. Easiest way to fix this is to install updates.
-
What happens when you just open a browser and go to hwbot.org? If the certificate is deemed invalid, can you show the certificate properties? It should show exactly why the certificate is invalid. As for the others, the certificate is either still valid or they don't check the certificates for uploading.
-
Yes, I think that's it. Have you tried the update? Does it work? https://www.catalog.update.microsoft.com/search.aspx?q=kb3140245 If it works, I will add it to the install readme of the manual installer!
-
This should work when installing the hwbot certificate from BenchMate's manual installer. If it doesn't work, please let me know.
-
It's done and currently in its testing phase. I am taking my time on this because I have a lot on my plate right now and the benchmark is huge and very different from its predecessors (it uses the Redshift renderer now).
-
Does it work without BenchMate? Because that looks like an Intel OpenCL error to me.
-
Your BenchMate files are either not valid (a file might be missing or corrupt - happens on bluescreens, try to reinstall BM) or if the Windows has not been on the internet for a long time (the many txt files suggest that), you need to install the SSL.com certificates, that BenchMate's file have been signed with. You can find the certificates in BM\res\certificates\install-run-as-admin.bat. You need to run that file with admin privileges. I thought about improving that error message. It happens too often and needs to be better balanced between security and practicability.
-
1) It's just a warning, you can ignore it. As you can see in the result window CPUID and SMBIOS show two different brand strings. But they are both saying it's the same CPU, so the result is good. This is a BIOS Implementation error. Although I could loosen up the validation and allow brand strings with different postfixes. Let me think about it. 2) It's a Windows 7 bug. ACPI PM timer is hogged, no idea why. You need to wait for 2 or 3 minutes so Windows allows to query the timer properly.
-
BenchMate 11.3 is out now. This release shows some love for legacy platforms! ? Intel CPUs prior to Nehalem will be benchable again if the system's hardware timers are stable. Yes, that means LGA 775 is back in the game. Thanks to @TheQuentincc for his bug report. And Windows 7 now has a Manual Installation guide. It's basically a big zip file you can download from the website. After unpacking there is an INSTALL.txt file, that guides you manually through the more difficult steps to make BenchMate and HWBOT submission work on legacy operating systems. Download: https://benchmate.org/ Changelog: https://benchmate.org/changelog/11.3.0 Donate: https://www.patreon.com/benchmate
-
@Monabuntur I did some further testing with the new PYPrime version, but the time ran out so the new category is still using PYPrime 2.0.
-
BenchMate 11.2 is now available for download. It adds PYPrime 32b for the HWBOT Country Cup Memory Stage and fixes a couple of bugs, that have been reported. Download: https://benchmate.org/ Changelog: https://benchmate.org/changelog/11.2.0 Donate: https://www.patreon.com/benchmate
-
OpenCL runtimes in use?
-
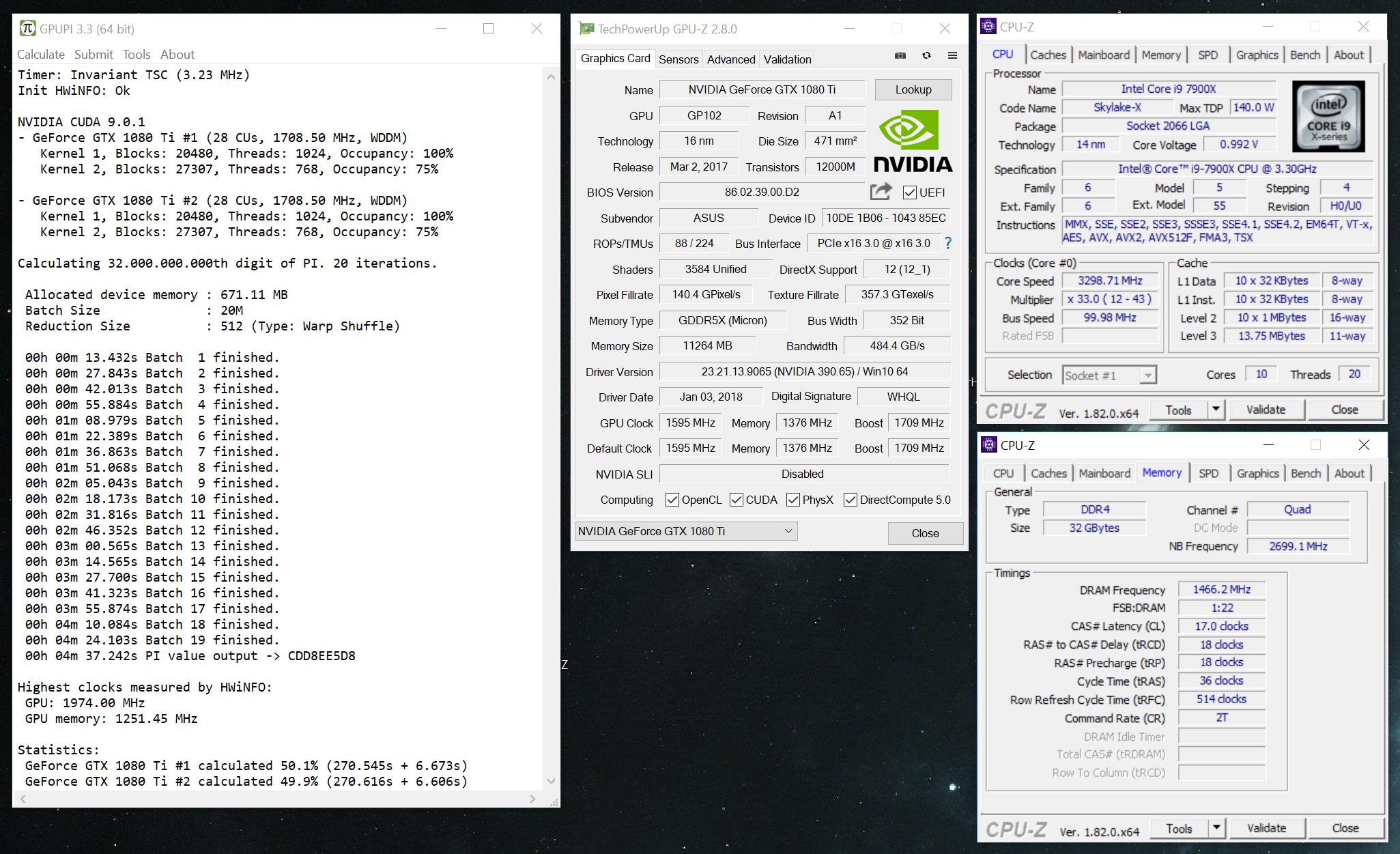
 Btw, you can see all Intel OpenCL tweaks in the result window. IOCL Vectorizer Off and AVX2 is the key here. These tweaks are possible with or without BenchMate and have been for many years. Now we have some transparency on Intel OpenCL settings.
Btw, you can see all Intel OpenCL tweaks in the result window. IOCL Vectorizer Off and AVX2 is the key here. These tweaks are possible with or without BenchMate and have been for many years. Now we have some transparency on Intel OpenCL settings. -
I had a change of heart and tried to get the download below 600 MB. It can be added manually with the + button. If it's often used, just let me know and I will bundle it again.
-
Let me check tomorrow. I am still sick, but tried my best to release today.

