noizemaker
-
Posts
485 -
Joined
-
Last visited
-
Days Won
21
Content Type
Profiles
Forums
Events
Blogs
Everything posted by noizemaker
-

HWBOT NEW GUI FEEDBACK THREAD
noizemaker replied to Leeghoofd's topic in HWBOT Development: bugs, features and suggestions
It’s unfortunate that no modern CSS frameworks have been implemented here. Using something like Tailwind CSS or Bootstrap could make the site fully responsive without adding much extra work. For fonts, I’d suggest something like "Inter," which is a variable font and thus easily adaptable. There are plenty of UI/UX designers who could handle the prototyping for a reasonable price, ensuring thoughtful positioning and presentation. Often, developers aren’t designers and vice versa, so collaborating with specialists can make a big difference. I’d recommend restoring the familiar, original design as a foundation, then gradually expanding in the UAT phase with community feedback. Additionally, I noticed no posts on the homepage announcing that help was needed, which could have been communicated more effectively. regards -
pushy
-
added stuff ?
-
added stuff
-
stuff added
-
big utils great run
-
nice run :-)
-
fastest ych ever :D niceee
-
pow pow nice benching
-
nice benching
-
stuff added
-
great resume for the hall of fame, awesome
-
great run ?
-
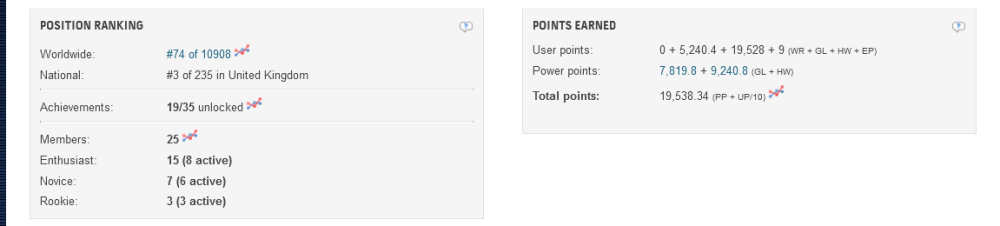
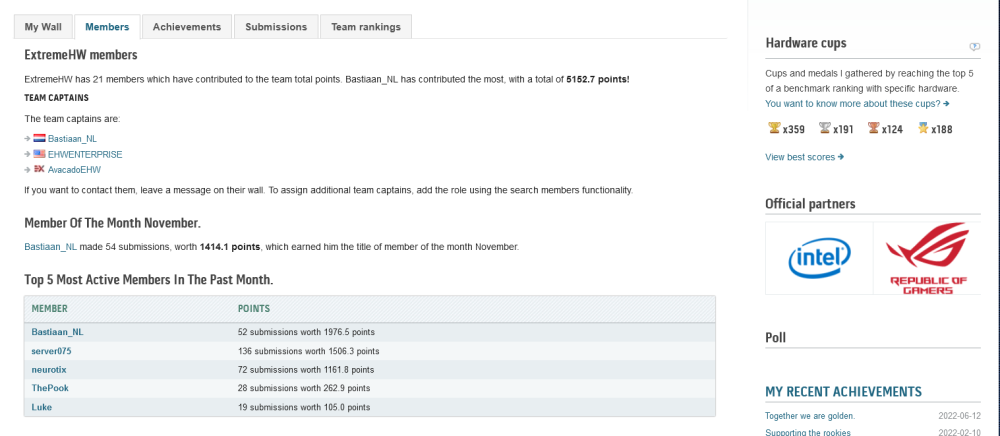
plain and simple html scraping works ? the api is broken/death in my scraper i just traverse one html with ~5kb once a day, so less then a regular pageload, keep that in mind we dont want to hurt the bot. would suggest to just scrape the teampage to keep the "load" close as possible, every information should be there. https://hwbot.org/team/extremehw/
-
close to 300k ? nice run
-
rerun with volcano ? laaaaater
-
thanks gentlemens
-
nice run :-))
-
Seby9123 - Core i3 12300 @ 6510.2MHz - 5025 cb Cinebench - R20
noizemaker replied to WestmereX's topic in Result Discussions
insane chip ?, congrats! -
sandwich power :D nice run
-
nearly 7.8g greaaat run
-
next level clocks ? niceeee run
-
look who is back :D nice run
-
nice run ?